

一、Redis实战之场景1:缓存穿透
1、正常流程
项目中使用缓存Redis查询数据的正常流程,如下图
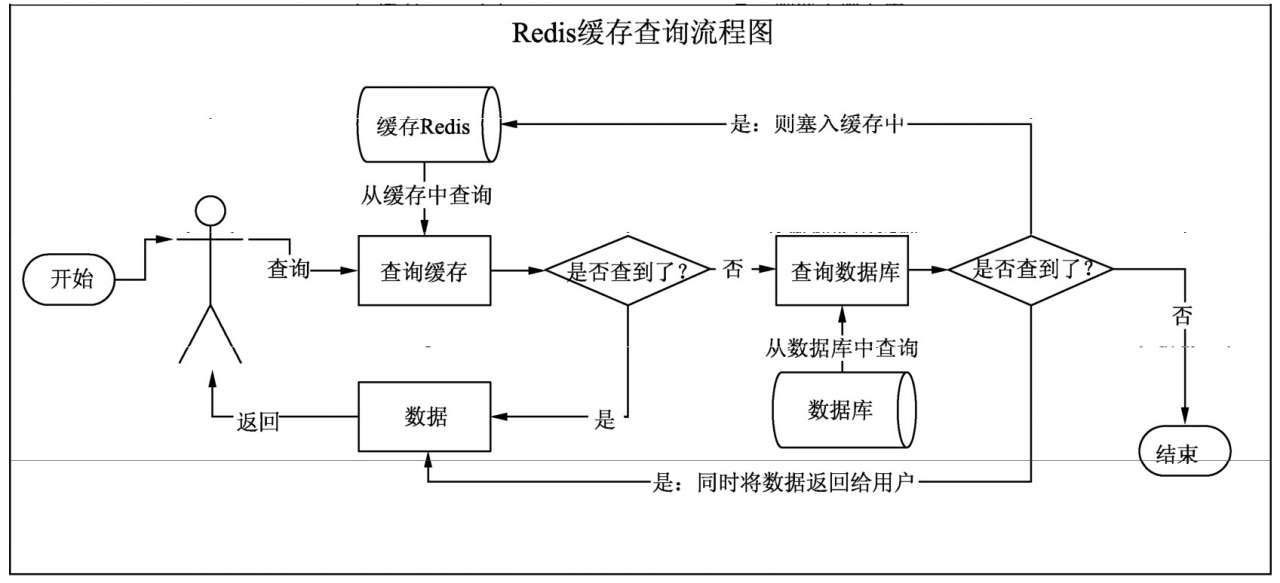
- 前端用户要访问获取数据时,后端首先会在Redis中查询
- 如果能查询到数据,则直接将数据返回给用户,流程结束
- 如果查不到数据,就前往数据库中查询,如果能查到数据,将数据返回给用户,同时将数据塞入缓存Redis中,流程结束
- 如果在数据库中没有查询到数据,则返回null,同时流程结束。
2、问题分析
当查询数据库的时候如果没有查询到数据,就直接返回null给前端用户,流程结束,如果前端频繁发起访问请求,恶意提供数据库中不存在的Key,则此时数据库中查询到的数据永远为null。由于null数据是不存入到Redis中,所以每次访问请求时将查询数据库,如果此时有恶意攻击,发起“洪流”式的查询,则很有可能会对数据库造成极大的压力,甚至压垮数据库。这个叫缓存穿透,就好像永远越过了缓存而直接永远的访问数据库。
3、解决方案
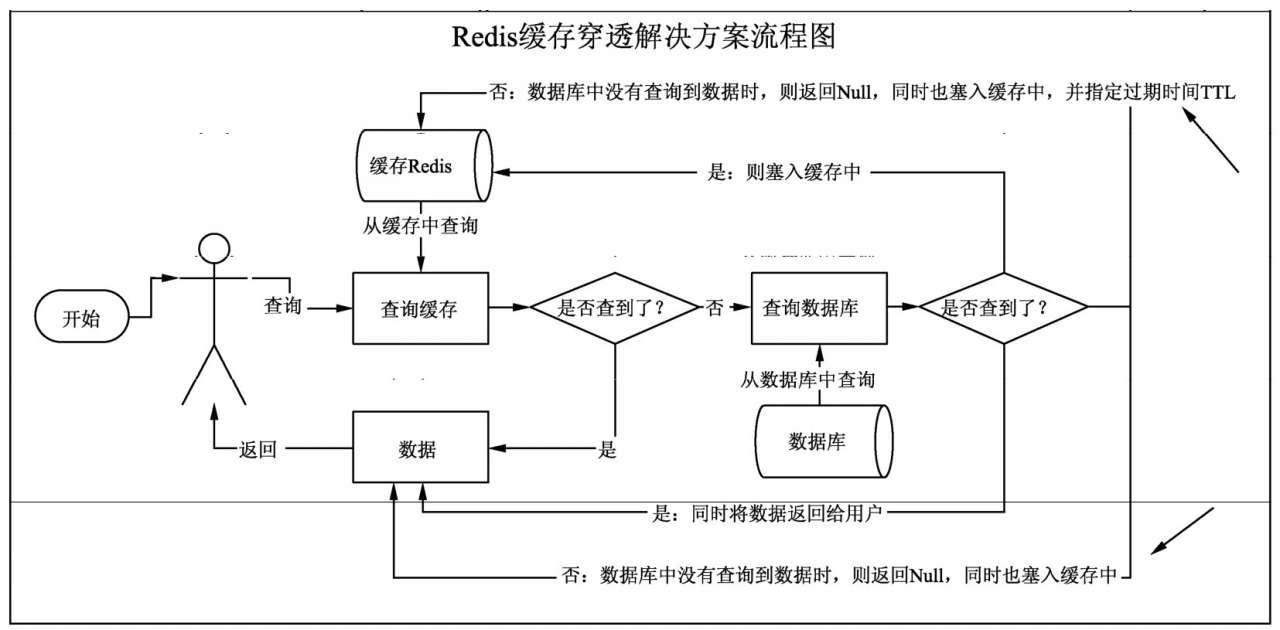
当查询数据库时,如果没有查询到数据,将null返回给前端用户,同时将该null数据塞入Redis,并对对应的Key设置一定的过期时间,流程结束,具体过程如下图
4、实战过程
1、建立数据库连接
1 | #redis |
2、引入依赖
1 | <!-- jpa--> |
3、实体类Person
1 | package com.victor.model; |
4、操作数据库的PersonRepository
1 | package com.victor.repository; |
5、操作Redis的CachePersonService
1 | package com.victor.service; |
6、前端控制器CachePersonController
1 | package com.victor.controller; |
二、Redis实战之场景2:缓存雪崩
在某个时间点,缓存中的key集体发生过期失效使得大量查询数据的请求都落到了DB上,导致数据库负载过高,压力暴增,甚至有可能压垮数据库。
原因分析:
- 大量的key在某个时间点或者某个时间段过期失效导致。
- 为了避免这种问题发生,一般的做法是给这些key设置不同的过期时间,随机的TTL,从而错开Redis中的key失效时间点,可以在某种成都上减轻数据库的压力。
三、Redis实战之场景3:缓存击穿
- Redis中某个频繁被访问的key或者叫热点key,在不停地扛着前端的高并发请求,当这个key突然在某个时间过期失效的是偶,持续的高并发访问请求就会穿破缓存,直接请求数据库,导致数据库压力在某一瞬间暴增。
- 原因分析:
- 主要是热点的key过期失效
- 实际开发中,既然这个key被当做频繁访问,那么就给这个key设置永不过期,这样前端的请求将几乎永远不会落在数据库上。
四、总结
不管是缓存穿透,缓存雪崩,缓存击穿,其实它们最终导致的后果几乎都是一样的,给数据库造成压力,甚至压垮数据库。解决方案也都有一个共同特征,就是加强防线,尽量让高并发的读请求落在缓存中,从而避免直接跟数据库打交道。

- 本文作者: Victor Dan
- 本文链接: https://victorblog.github.io/2018/06/17/Redis实战与总结/
- 版权声明: 本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议。转载请注明出处!